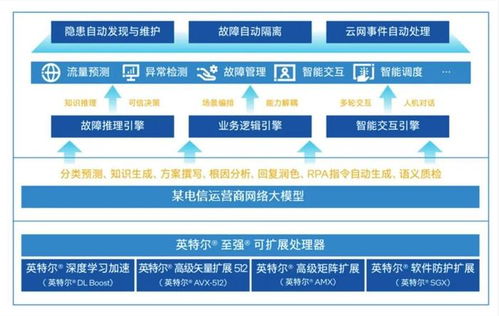
在人工智能技术飞速发展的浪潮中,中国首个网络大模型的诞生,标志着国内在AI网络工程领域迈出了重要一步。令人瞩目的是,这一模型在硬件架构上,并未一味追逐当前流行的GPU或TPU,而是“pick”了CPU作为其核心计算单元,这背后蕴含着对网络工程深层次的战略考量与技术洞见。
网络大模型,顾名思义,是专门针对网络空间进行优化设计的大型人工智能模型。它不仅要处理海量的网络数据,还需理解复杂的网络拓扑、协议交互及安全态势,其应用场景涵盖智能路由、流量优化、网络安全防护乃至未来6G网络的自主管理等。选择CPU,首先源于其卓越的通用性与灵活性。与专为并行计算设计的GPU不同,CPU在复杂的、串行逻辑处理以及任务调度方面具有天然优势。网络工程中的许多核心任务,如协议栈解析、策略决策、异常检测等,往往涉及大量条件判断和状态管理,这正是CPU所擅长的领域。CPU生态系统成熟,软件开发工具链完善,便于模型的快速迭代、部署和维护,这对于需要高可靠性和持续演进的网络基础设施至关重要。
这一选择体现了对“算力效能比”与“自主可控”的平衡追求。虽然GPU在训练某些AI模型时拥有更高的峰值算力,但其功耗、成本以及对特定软件框架的依赖也是不容忽视的因素。尤其是在大规模网络节点部署的场景下,成本与能效至关重要。成熟的CPU架构,特别是在国产CPU技术不断突破的背景下,能够提供更可控、更经济的算力基础,有利于构建安全、可靠且可持续的网络AI能力。这并非是对先进计算硬件的排斥,而是强调“适合的才是最好的”——针对网络工程特有的低延迟、高可靠、强逻辑的需求,经过深度优化的CPU集群可能比单纯的算力堆砌更具实际效能。
从网络工程的发展脉络看,其核心一直围绕着连接、管理与控制。CPU作为传统计算的核心,与网络设备(如路由器、交换机)的历史结合更为紧密。选择CPU作为网络大模型的基石,有利于实现AI技术与现有网络硬件体系、管理系统的平滑融合与渐进式创新,减少技术断层带来的风险与成本。这或许是一种更为务实和稳健的技术路线,旨在让强大的AI能力能够扎实地赋能于每一层网络架构,而非悬浮于尖端硬件之上。
这并不意味着CPU是唯一的选择。未来的网络大模型很可能走向异构计算架构,根据任务负载动态调配CPU、GPU乃至新型处理器的资源。但中国首个网络大模型从CPU起步,清晰地向业界传递了一个信号:在追求AI与网络深度融合的道路上,深刻理解业务本质、注重实际效能与长期可控性,与追求算力指标同等重要。它为中国乃至全球的网络智能化发展,提供了一条值得深入探索的特色路径。